Mistake 11: Not shuffling the training data
In machine learning, some models are sensitive to data ordering, specially those based on gradient optimization and/or batch learning such as neural networks and many of their variants like Convolutional Neural Networks, Autoencoders, Generative Adversarial Networks, and so on. Shuffling the data (rows) helps to avoid bias from data ordering, improve generalization, and stabilize parameter learning. Shuffling helps having more representative batches of the overall data distribution.
Not all machine learning models are sensitive to data ordering. For example, KNN or tree based models like decision trees, random forest, and XGBoost are not affected by data ordering.
The following code loads the WISDM dataset. Figure 11.1 shows the first ten rows.
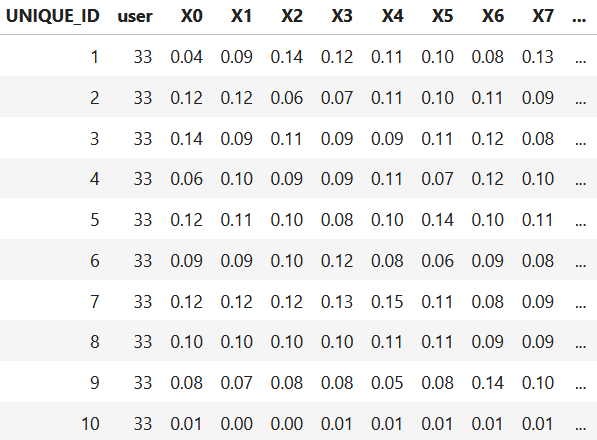
Figure 11.1: First rows of WISDM dataset.
Here, you can see that the rows are sorted by user. You can easily shuffle the rows with the sample() function as follows.
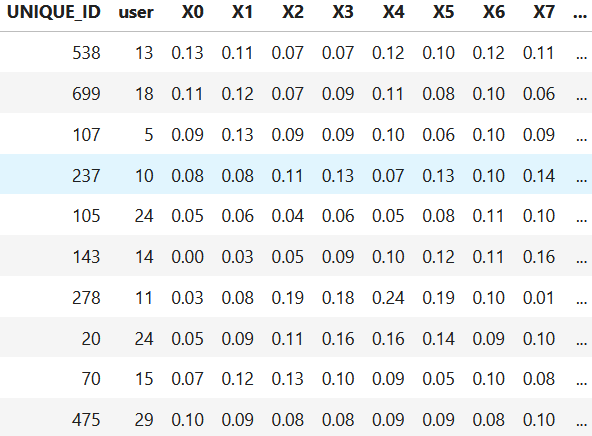
Figure 11.2: First rows of WISDM dataset after shuffling.
Figure 11.2 shows the result of shuffling the rows. The frac = 1 parameter indicates the fraction of data to be sampled without replacement. In this case, we want all data back so it is set to \(1\). When splitting the data using train_test_split(), the data will also be returned in a random order.