Mistake 10: Injecting data into the test set
Data injection is one of the most common mistakes in machine learning and it materializes in many different ways. When assessing the generalization performance of a model, an independent test set is used to compute performance metrics like accuracy, precision, f1-score, etc. The keyword here is: independent. This means that the trained model should not have any information about this independent set. However, there are many ways in which we can inadvertently violate this assumption by ‘injecting’ information into the model that it should not have at test time. This typically happens when applying preprocessing procedures like normalization or class balancing methods.
To demonstrate this, we will import the IRIS dataset and train a KNN classifier. First we load the dataset and print some summary statistics. Figure 10.1 shows the output of the describe() function.
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
data = load_iris(as_frame=True)
data.frame.describe()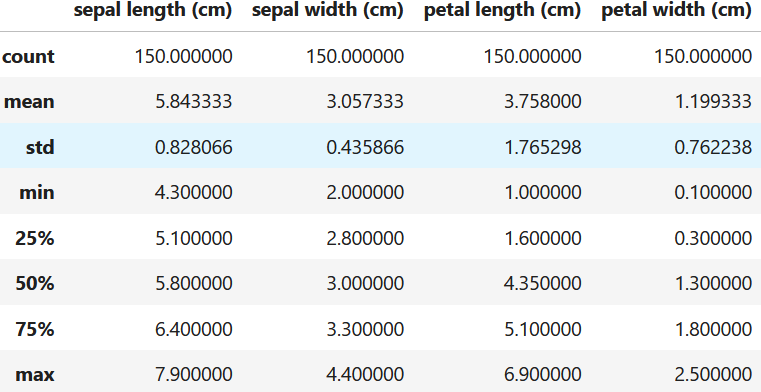
Figure 10.1: IRIS dataset summary.
By looking at the statistics, we notice that the columns have different ranges so we decide to normalize the features, split the data, and train the classifier.
X = data.data
y = data.target
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y,
test_size = 0.5,
random_state = 123)
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy with data injection: {accuracy:.2f}")So what is wrong with the previous code? In line \(4\) the entire dataset is normalized using MinMaxScaler(). In order to normalize the data, some parameters need to be learned. In this case, the minimum and maximum values of each feature. However, these parameters are being learned from the entire dataset. When the data is split into train and test sets (line \(5\)) some information from the train set may have leaked into the test set. This is because the minimum (or maximum) value of one of the features, could belong to an instance from the train set. But these values were used to normalize data that also belong to the test set. Typically, this leads to overestimation of performance metrics. In this case the accuracy was \(0.95\).
The correct way to normalize the data is to first, learn the parameters from the train set and then, use those parameters to apply the transformation to the test set. In the following code, the data is first split into train and test sets. Then, the normalization parameters are learned (and applied) only from the train set (line \(5\)). The test set is then normalized with the previously learned parameters (line \(6\)).
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.5,
random_state = 123)
scaler = MinMaxScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train_scaled, y_train)
y_pred = knn.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy without data injection: {accuracy:.2f}")In this case, the accuracy was lower (\(0.93\)) however, this performance estimate represents better the performance at test time.