Mistake 16: Ignoring inter-user variance
There are systems that rely on individual user behaviors. For example, hand gesture recognition, activity recognition, and speech recognition systems, to name a few. These systems are called multi-user systems (Garcia-Ceja 2021). Take for example, a hand gesture classification problem based on wrist-movement data (taken from an accelerometer embedded in a smartwatch). Each person has their own way of performing the gestures and every person will perform the gestures at different speeds, wrist-orientations, etc. Those differences in the captured signals generate variance across users. In fact, there are also differences within the same user in the way they perform the same gesture multiple times but we expect the intra-user differences (variance) to be smaller compared to the inter-user differences. This inter-user variance can have a huge impact when evaluating the performance of a model.
Typically, the performance of a classifier is evaluated using \(k\)-fold cross validation or hold-out validation. In a multi-user scenario, this will result in data from the same users being present in both, the train and test sets at the same time. This means that the trained model will already have some information for any particular user in the test set. This will allow the model to make accurate predictions for the data in the test set. However, if a completely new user wants to use the system the performance is likely to degrade since the train set did not include any information about the new user. That is, if the system is to be used by new users without going into a calibration (re-training) phase, the estimated performance metrics are likely to be overestimated. A model that is trained with data from multiple users using validation schemes like \(k\)-fold cross validation is called a mixed model. This is because the data from multiple users is mixed as if there were only a single user.
In order to have a better performance estimate when the system is deployed and tested by new unknown users you can build user-independent models (one for each user). A user-independent model is built by taking a user of interest \(u\) and excluding all their data from the training set. Then, only use the data from user \(u\) as the test set. When repeating this process for every user in the database, it is called leave-one-user-out validation. Figure 16.1 depicts this process.
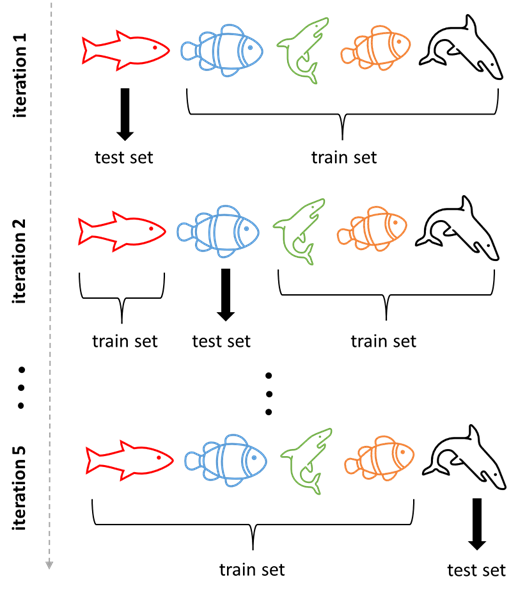
Figure 16.1: Procedure of the leave-one-user-out validation scheme. At each iteration, the data from a particular user is exclusively included in the test set and the rest is added to the train set. Each fish represents all of its instances (not necessarily only one data point).
This validation scheme will provide more accurate estimates of your model when deployed in real life. This does not mean that a user-independent model is better than a mixed model. The evaluation scheme you use will depend on your use case. A mixed model is completely fine if it is guaranteed that data from the final user will be included in the training phase. For example, asking the user to go through a calibration phase.
The following example uses the WISDM dataset for activity recognition. The dataset includes data from \(36\) users. The next code snippet uses a mix-model approach by performing \(10\)-fold cross validation. The user column which identifies every user with an id, is removed before splitting the data.
from sklearn.model_selection import StratifiedKFold
X = df.drop(columns=['class','user']).values
y = df["class"].values
kf = StratifiedKFold(n_splits = 10)
accuracies = []
for i, (train_indx, test_indx) in enumerate(kf.split(X, y)):
X_train = X[train_indx]
y_train = y[train_indx]
X_test = X[test_indx]
y_test = y[test_indx]
rf = RandomForestClassifier(random_state = 123)
rf.fit(X_train, y_train)
predictions = rf.predict(X_test)
accuracies.append(accuracy_score(y_test, predictions))
print(np.mean(accuracies))The following code performs a leave-one-user-out evaluation. That is, it trains user-independent models. The LeaveOneGroupOut validator splits the data such that all instances in the training set are part of all groups except one. In this case, the group corresponds to the user id. That is, each user belongs to their own group.
from sklearn.model_selection import LeaveOneGroupOut
users = df["user"].values
X = df.drop(columns=['class','user']).values
y = df["class"].values
valscheme = LeaveOneGroupOut()
accuracies = []
for train_indx, test_indx in valscheme.split(X, y, groups = users):
X_train = X[train_indx]
y_train = y[train_indx]
X_test = X[test_indx]
y_test = y[test_indx]
rf = RandomForestClassifier(random_state = 123)
rf.fit(X_train, y_train)
predictions = rf.predict(X_test)
accuracies.append(accuracy_score(y_test, predictions))
print(np.mean(accuracies))Here, you can see that the accuracy significantly dropped with the user-independent models, thus, providing a better estimate on the expected performance with unknown users.